Recap of Last Lesson: We learned about robots.txt and how websites prevent being indexed by search engines.
Objective
Find the password to log into level 5.
Intel Given
- URL: http://natas4.natas.labs.overthewire.org/
- Access Disallowed
How to
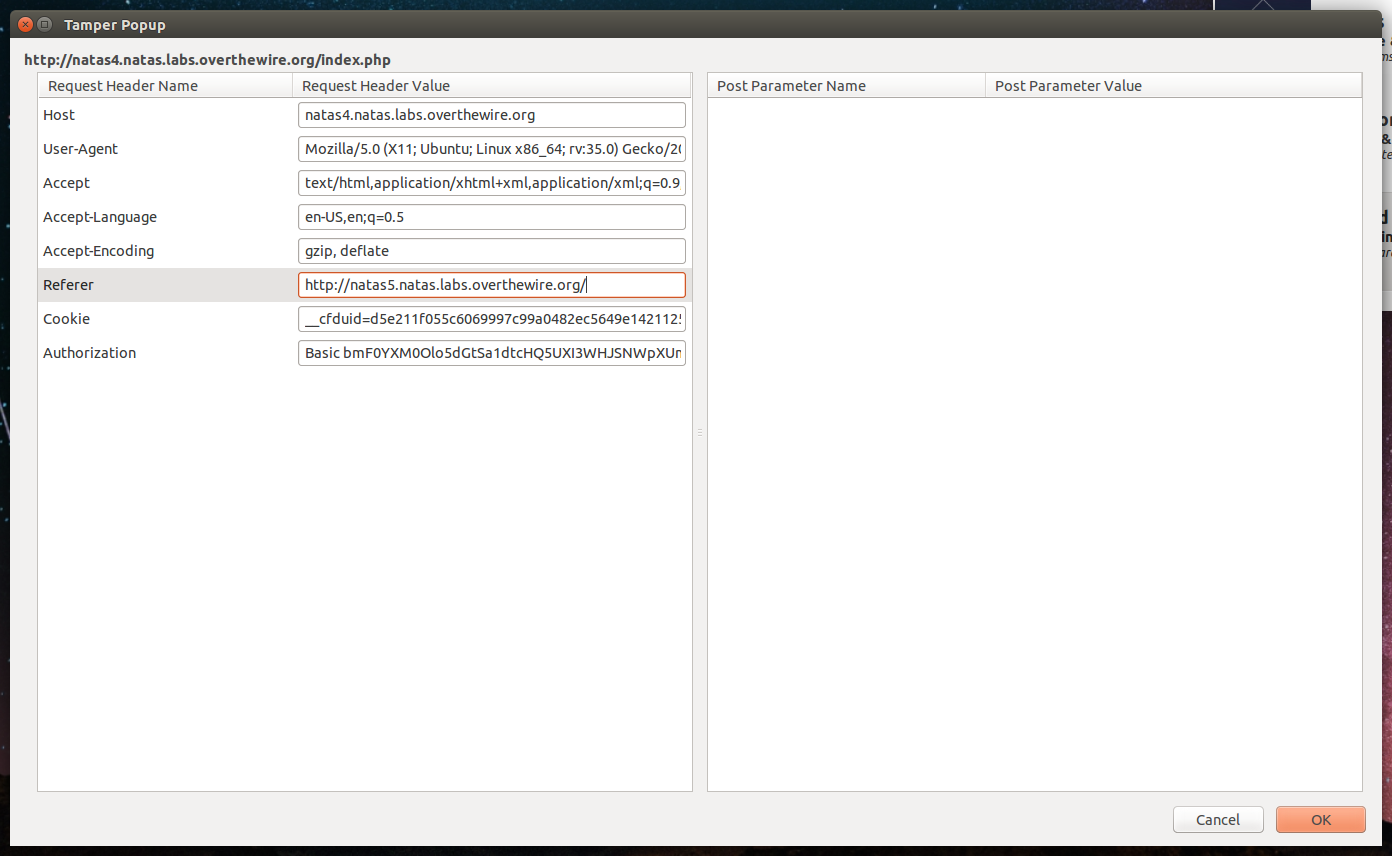
When we come to the page we are greeted immediately by an error message. It says, “Access disallowed. You are visiting from ” ” while authorized users should come only from “http://natas5.natas.labs.overthewire.org/”. What is inside the quotes may vary for you, if you just pasted the URL in your browser it will be blank like it is for me. So the question is now, how does the page know where we came from? To understand this, we need to learn a little about HTTP. HTTP is an important protocol to understand, I suggest you take some time to learn as much about it as you can. Hopefully, through your research you should have come to take a look at the different HTTP Request fields. Find anything that looks like it might give information where we are coming from? If not, look harder. Still stumped? Check it out here.

{kind=link}
{kind=link}
{kind=link}
{kind=link}